Nex-N2-Pro: Model Agentic Mới Với Benchmark Rất Cao
· 5 phút để đọc
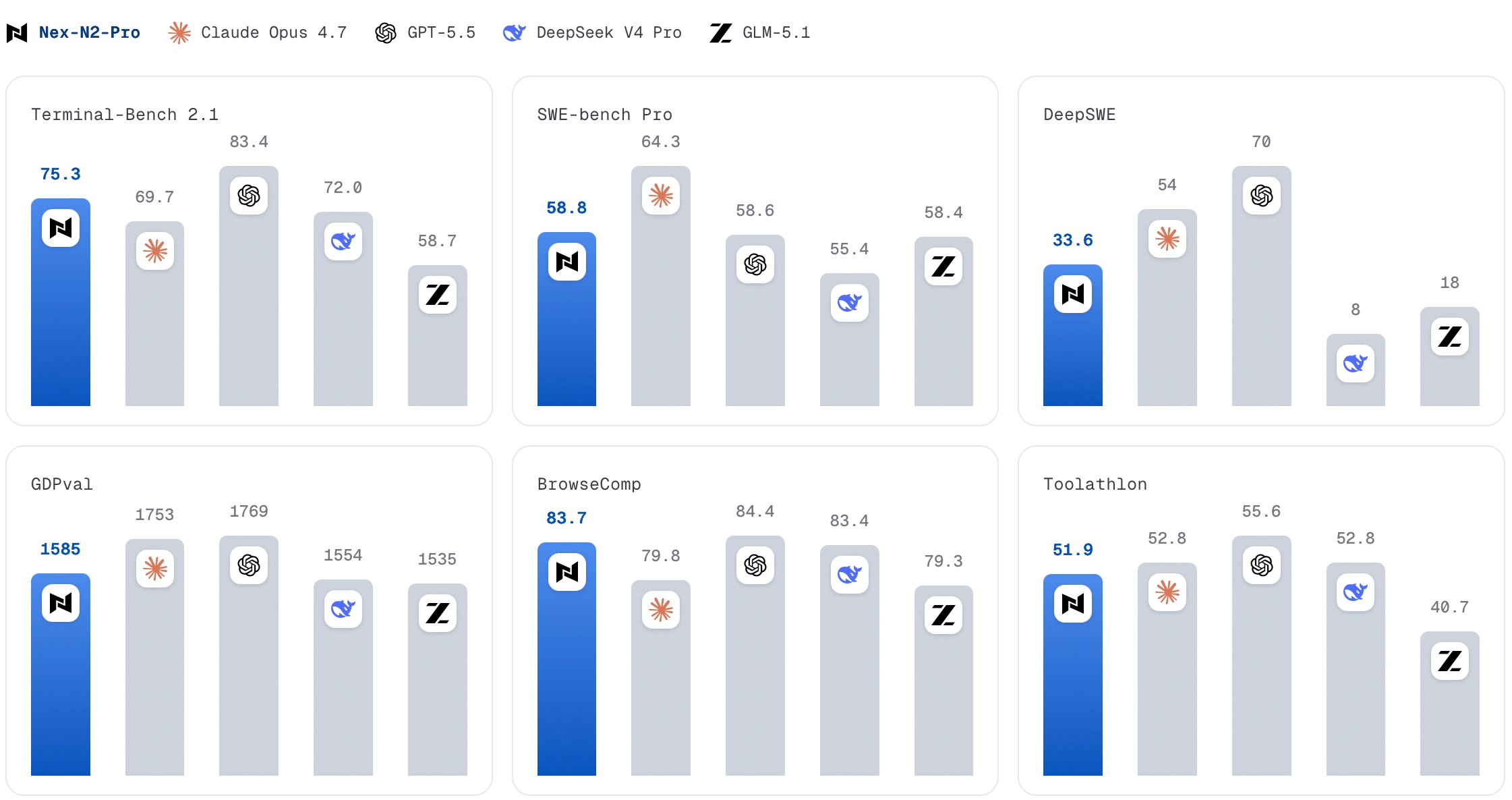
Nex AGI vừa công bố Nex-N2-Pro, một model agentic open-source mới nhắm thẳng vào nhóm use case đang nóng nhất hiện nay: coding agent, tool use, terminal execution và các workflow dài hơi có feedback từ môi trường thật.
Điểm gây chú ý không phải chỉ là "thêm một model LLM mới", mà là bảng benchmark được công bố: Nex-N2-Pro đạt 80.8 trên SWE-Bench Verified, 75.3 trên Terminal-Bench 2.1, 58.8 trên SWE-Bench Pro, 83.7 trên BrowseComp và 90.7 trên GPQA Diamond. Nếu các con số này được kiểm chứng độc lập, đây là một trong những model open-source đáng theo dõi nhất cho agentic coding trong năm nay.